What is Base64?
Base64 is a common encoding used to represent data as plain text.
Slightly Longer Answer
Base64 encodes every 6 bits of data into a series of letters, digits, plus signs (+), and forward slashs (/). Also sometimes up to two equal signs (=) are added to the end for padding.
Why Use Base64
To store embed binary data inside some kind of text format. For example embeding a JPEG inside an HTML file.
How Base64 Encoding Works
The best way to understand how it works is to look at an encoding you already know.
You might not realize it but when you write down a number you're using decimal encoding, which is not that different from Base64 encoding.
Decimal Encoding
With decimal encoding you have 10 digits to choose from. Those digits, of course are:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
So what are the rules for using those digits for encoding a number? Well when we count, we always switch to the digit digit in the set. A 0 becomes 1, a 1 becomes 2, and so on. So that's our first rule:
Count up by switching to the next digit.
But that only lets us count up to 9. How do we count higher?
That leads us to our 2nd rule, when we reach the last digit, we change it back to the first digit and add a digit to our number.
So counting up from "9" gives us "10".
If we run out of digits, switch to the first digit.
And add a digit
to our number.
What about when we count from "19" to "20", we don't add a digit, instead we count using that digit.
That gives us our 3rd rule.
If we run out of digits, switch to the first digit.
If there's a digit in front of it we count up.
And that's it, those are our tree rules.
Except... there's actually only two rules.
That's because Rule #2 and Rule #3 are really the same rule.
See all numbers have an invisible zero in front of them, so a "9" is the same as a "09", that's why we don't bother writing the zero, because it doesn't change the meaning of the number.
So really we're counting up from an invisible 0. Rule # 3 already says we could count up using the next digit.
So there are only two rules:
Only Two Rules
Count up by switching to the next digit.
If we run out of digits, switch to the first digit.
Count up the digit in front of it.
(remember the invisible zeros)
Click the buttons below to see these rules in action:
Decimal Encoding
As I mentioned earlier other encodings use the same rules, the only difference is that instead of using the digits 0 through 9, they use something else.
Let's make up our own encoding using Emojis to see what it would look like:
Emoji Encoding
Now let's see what would happen if we change the number of emojis we use. Let's bring it down to just 3:
Three Emoji Encoding
We've now opened the door to many other common encodings. For example "binary encoding" is the same as decimal encoding except it only uses two digits instead of 10. Those digits of course being 0 and 1:
Binary Encoding
This collection of "things" that we use in our encodings, whether they are digits or Emojis, or anything else, are called symbols.
So what else can we use aside from digits and emojis? How about letters?
In fact, that brings us to another common encoding "hexadecimal". Hexadecimal has 16 symbols.
The digits 0 through 9 and the letters A through F. And it looks like this:
Hexadecimal Encoding
Finally this brings us to Base64, as you've probably figured out by now Base64 has 64 symbols. Those symbols are:
- Uppercase Letters "A" through "Z"
- Lowercase Letters "a" through "z"
- Digits 0 through 9
- the plus sign (+)
- and the forward slash (/)
And looks like this:
Base64 Encoding
What does the equal sign mean?
If we already have 64 symbols, why is there also an equal sign (=)? The answer is that the equal sign is not used to encode data, it's used in some cases to pad the encoded data.
The padding makes it so that the number of symbols in the encoded output is always a multiple of 4.
This allows it to align better with the fact that computers store data in sets of 8 bits. Since a symbol in Base64 represents 6 bits, 4 symbols represent 24 bits, which works out to exactly 3 bytes.
Having the data padded like this would simplify the decoding algorithm. Since the algorithm could always count on being able to read 4 symbols at a time and output 3 bytes for every 4 symbols.
Technically algorithms should be able to encode and decode Base64 without any padding, and some do.
Also because padding is added to make sure the length is a multiple of 4. This means padding isn't always added anyway, since the number of symbols in the encoded data might already be a multiple of 4.
Finally because encoding 1 byte results in 2 Base64 symbols, 2 bytes in 3 symbols, and 3 bytes in 4 symbols. The most amount of padding you could have is 2 equal signs.
In practice, including padding in encoded data ensures that it will work with all Base64 decoders. But if you know the decoders you are working with don't require it, you can choose to not use padding.
Why These Specific Symbols?
Base64 could have used any 64 symbols - which begs the question why these symbols?
It's because they are widely compatible. There are a lot of types of computers and devices out there, and they are running different operating systems, browsers, and software, in all kinds of different languages.
The fact is that not all characters play well on all these systems. Base64 attempted to select characters that were the most compatible across the board.
This allowed people to copy and paste and share Base64 content and have it work. It also allowed them to embed Base64 in other plain text content, like JSON, or a plain text email protocol.
As far as the exact choice of symbols - letters and numbers were a safe bet. But that only came out to 62 characters, so they still needed two more.
They chose the other two from the standard 7-bit ANSI character set as well. They tried to choose characters that were not often used for other things, that way it could be shared and embedded more easily.
For example they wouldn't want to use the null character, because that was often used to indicate the end of a string of text. Some characters had special meaning to printers, while another triggered a bell sound. Quote characters like single (') and double quote (") had special meaning in programming languages.
Once all of those characters were ruled out, they could pretty much choose randomly from what was left.
Chances are if they were to select those two characters today they would probably have chosen differently.
That's because today the plus sign (+) and forward slash (/) have special meaning in URLs, and since URLs are widely used today, they would probably have ruled them out and picked something else.
If you want to use Base64 in URLs today you either have to escape those characters or make sure to swap them with something else, then make sure to swap them back before decoding.
The method used by python is to replace the plus sign with a minus sign (-) and the forward slash with an underscore (_).
Why Base64? Why not 63 or 65?
Encodings can have any number of symbols, but to make them more convenient to use with computers it's easier if the number of symbols aligns with a certain number of bits.
For example hexadecimal has 16 symbols, which is the number of values that can be represented with 4 bits. Similarly 6 bits can represent 64 numbers which is what makes Base64 more convenient than Base63 or Base64.
Why Encode Data? Why Not Leave it in Binary?
It depends on the situation. If you are attaching an image to an email for example, it doesn't make sense to convert it you can just attach it as is.
But there are a lot of situations where it's useful to have the data available as text. Usually when you're only allowed to or it's convenient to use text.
For example JSON is a purely a text format, so the only way to embed binary data in it is to encode it as text. HTML is another text format, it allows embedding content like images, but again since it's a text only format binary has to be encoded as text in order to be included.
What Base64 Actually Looks Like
We've talked a lot about Base64 encoding, and as you can imagine the final output is just a series of Base64 characters. For the sake of completion though let's take a look at a real example.
A common type of binary files are images. Take this one for example:

If we were to open up this file to look at the bits and bytes that make it up, the first 10 bytes would look like this:
Encoding all 776 bytes of this image into Base64 would generate the following output:
An example of using this Base64 output would be to embed the image into HTML. HTML supports "data urls", with the proper syntax it lets you embed images using Base64.
The image above was displayed using the following code:
<img src="what-is-base64/among-us-red-guy.jpg" />
Using data urls would change it to something like this:
<img src="data:image/jpg;base64,..." />
We would just need to replace the three dots (...) with the Base64. The output would look just like the original except now the image is embedded right into the HTML instead of being a separate file:

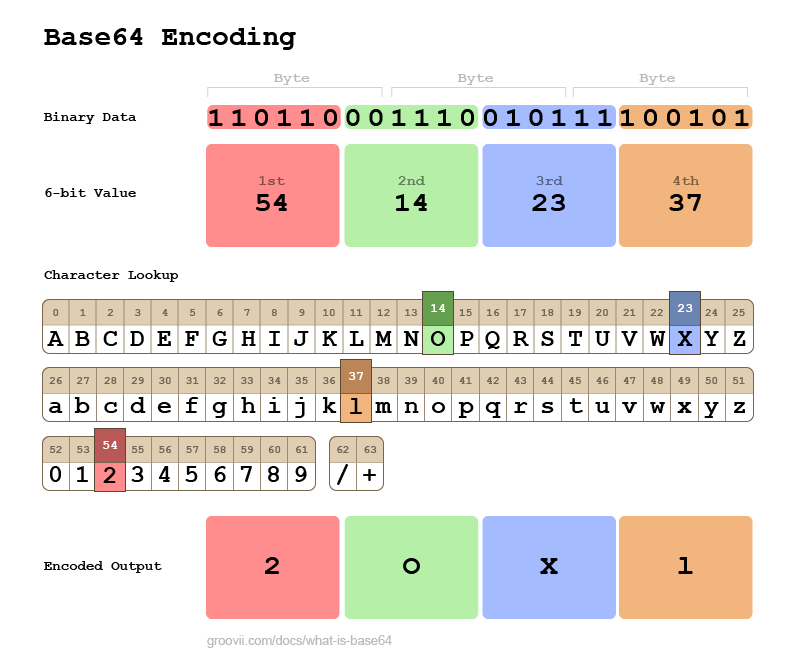
Illustrated Overview
The graphic below illustrates the parts of the Base64 encoding process. You have the 3 bytes at the top broken out into 6-bit chunks, four of them.
The values of those 6-bit chunks are used to lookup a symbol from the Base64 character set. Finally those symbols are strung together to produce the Base64 output: 2OXl
How to Detect Base64
How can you tell if a series of characters represent Base64? The most accurate way to tell is to decode the string of characters and validate the output.
For example if the Base64 content is supposed to encode a JPEG image. Decode the Base64 and then run the code that processes the JPEG on the decoded bytes. If the bytes don't represent a JPEG then the code will fail.
Another approach is the checked the first seveal decoded bytes for identifying values. Many common file types hava a specific set of bytes at the start that help identify it (see File Magic Numbers).
This is not fool proof, since a set of random bytes might just happen to start with the same bytes as a file type. Also this wouldn't tell you if you had a complete file, just that you have some of the starting bytes.
We use the example of a JPEG here, but the same would be true for other formats. For example if the Base64 was supposed to encode JSON, you would decode the Base64, and then attempt to decode that output as JSON, and confirm that it decodes without error.
Custom Format
Alternatively you can define your own format for the binary content that you can design to be less expensive. For example you can prefix the binary data you are encoding with your own "Magic Number", and maybe include other information like number of bytes that were encoded, and/or a file hash.
If you don't control the encoding of data, and the data doesn't follow some verifiable structure, then there's another less effective technique you can use to check if it's Base64.
Analyze the Characters
You can confirm that the characters are within the Base64 character set. Meaning that the characters are in the set of the upper and lower case letters A through Z, or the digits 0 through 9, or the characters forward slash (/) or plus sign (+).
If you know padding is required in the coding you can confirm that the number of characters are divisible by 4. And that at most there are two equal signs (=) at the end.
This approach is not as effective as validating the decoded content because it's quite easy for random characters to look like Base64 and decode fine. Also just because it's valid Base64 doesn't mean the that decoded Base64 bytes are valid content.